4. Data Stores
In addition to transmitting data via publish/subscribe communication, Broker also offers a mechanism to store this very data. Data stores provide a distributed key-value interface that leverages the existing peer communication.
4.1. Aspects
A data store has two aspects: a frontend for interacting with the user, and a backend that defines the database type for the key-value store.
4.1.1. Frontend
Users interact with a data store through the frontend, which is either a master or a clone. A master is authoritative for the store, whereas a clone represents a local cache that is connected to the master. A clone cannot exist without a master. Only the master can perform mutating operations on the store, which it pushes out to all its clones. A clone has a full copy of the data in memory for faster access, but sends any modifying operations to its master first. Only when the master propagates back the change, the result of the operation becomes visible at the clone.
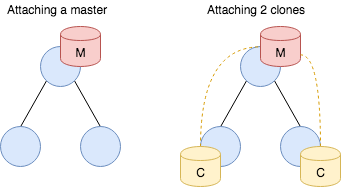
It is possible to attach one or more data stores to an endpoint, but each store must have a unique master name. For example, two peers cannot both have a master with the same name. When a clone connects to its master, it receives a full dump of the store:
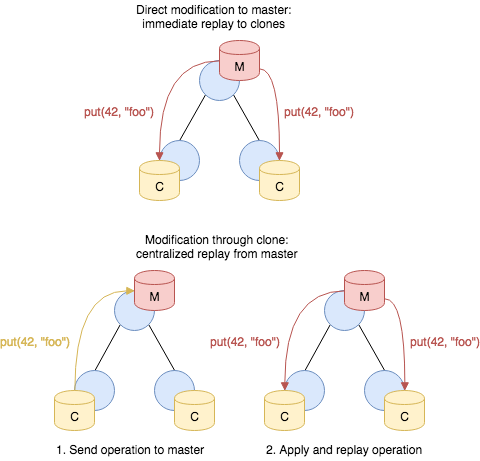
While the master can apply mutating operations to the store directly, clones have to first send the operation to the master and wait for the replay for the operation to take on effect:
4.1.2. Backend
The master can choose to keep its data in various backends:
Memory. This backend uses a hash-table to keep its data in memory. It is the fastest of all backends, but offers limited scalability and does not support persistence.
SQLite. The SQLite backend stores its data in a SQLite3 format on disk. While offering persistence, it does not scale well to large volumes.
4.2. Operations
Key operations on data stores include attaching it to an endpoint, performing mutating operations, and retrieving values at specific keys.
4.2.1. Construction
The example below illustrates how to attach a master frontend with a memory backend:
endpoint ep;
auto ds = ep.attach_master("foo", backend::memory);
The factory function endpoint::attach_master has the following signature:
expected<store> attach_master(std::string name, backend type,
backend_options opts=backend_options());
The function takes as first argument the global name of the store, as
second argument the type of store
(broker::backend::{memory,sqlite,rocksdb}), and as third argument
optionally a set of backend options, such as the path where to keep
the backend on the filesystem. The function returns a
expected<store> which encapsulates a type-erased reference to the
data store.
Note
The type expected<T> encapsulates an instance of type T or an
error, with an interface that has “pointer semantics” for syntactic
convenience:
auto f(...) -> expected<T>;
auto x = f();
if (x)
f(*x); // use instance of type T
else
std::cout << to_string(x.error()) << std::endl;
In the failure case, the expected<T>::error() returns the error.
4.2.2. Modification
Data stores support the following mutating operations:
void put(data key, data value, optional<timespan> expiry = {}) const;Stores the
valueatkey, overwriting a potentially previously existing value at that location. Ifexpiryis given, the new entry will automatically be removed after that amount of time.void erase(data key) const;Removes the value for the given key, if it exists.
void clear() const;Removes all current store values.
void increment(data key, data amount, optional<timespan> expiry = {}) const;Increments the existing value at
keyby the given amount. This is supported for numerical data types and for timestamps. Ifexpiryis given, the modified entry’s expiration time will be updated accordingly.void decrement(data key, data amount, optional<timespan> expiry = {}) const;Decrements the existing value at
keyby the given amount. This is supported for numerical data types and for timestamps. Ifexpiryis given, the modified entry’s expiration time will be updated accordingly.void append(data key, data str, optional<timespan> expiry = {}) const;Appends a new string
strto an existing string value atkey. Ifexpiryis given, the modified entry’s expiration time will be updated accordingly.void insert_into(data key, data index, optional<timespan> expiry = {}) const;For an existing set value stored at
key, inserts the valueindexinto it. Ifexpiryis given, the modified entry’s expiration time will be updated accordingly.void insert_into(data key, data index, data value, optional<timespan> expiry = {}) const;For an existing vector or table value stored at
key, insertsvalueinto it atindex. Ifexpiryis given, the modified entry’s expiration time will be updated accordingly.void remove_from(data key, data index, optional<timespan> expiry = {}) const;For an existing vector, set or table value stored at
key, removes the value atindexfrom it. Ifexpiryis given, the modified entry’s expiration time will be updated accordingly.void push(data key, data value, optional<timespan> expiry = {}) const;For an existing vector at
key, appendsvalueto its end. Ifexpiryis given, the modified entry’s expiration time will be updated accordingly.void pop(data key, optional<timespan> expiry = {}) const;For an existing vector at
key, removes its last value. Ifexpiryis given, the modified entry’s expiration time will be updated accordingly.
4.2.3. Direct Retrieval
Data stores support the following retrieval methods:
expected<data> get(data key) const;Retrieves the value at
key. If the key does not exist, returns an errorec::no_such_key.auto result = ds->get("foo"); if (result) std::cout << *result << std::endl; // Print current value of 'foo'. else if (result.error() == ec::no_such_key) std::cout << "key 'foo' does not exist'" << std::endl; else if (result.error() == ec::backend_failure) std::cout << "something went wrong with the backend" << std::endl; else std::cout << "could not retrieve value at key 'foo'" << std::endl;
expected<data> exists(data key) const;Returns a
booleandata value indicating whetherkeyexists in the store.expected<data> get_index_from_value(data key, data index) const;For containers values (sets, tables, vectors) at
key, retrieves a specificindexfrom the value. For sets, the returned value is abooleandata instance indicating whether the index exists in the set. Ifkeydoes not exist, returns an errorec::no_such_key.expected<data> keys() constRetrieves a copy of all the store’s current keys, returned as a set. Note that this is a potentially expensive operation if the store is large.
All of these methods may return the ec::stale_data error when
querying a clone if it has yet to ever synchronize with its master or
if has been disconnected from its master for too long of a time period.
The length of time before a clone’s cache is deemed stale depends on
an argument given to the endpoint::attach_clone method.
All these methods share the property that they will return the corresponding result directly. Due to Broker’s asynchronous operation internally, this means that they may block for short amounts of time until the result becomes available. If that’s a problem, you can receive results back asynchronously as well, see next section.
Note, however, that even with this direct interface, results may sometimes take a bit to reflect operations that clients perform (including the same client!). This effect is most pronounced when working through a clone: any local manipulations will need to go through the master before they become visible to the clone.
4.2.4. Proxy Retrieval
When integrating data store queries into an event loop, the direct
retrieval API may not prove a good fit: request and response are
coupled at lookup time, leading to potentially blocking operations.
Therefore, Broker offers a second mechanism to lookup values in data
stores. A store::proxy decouples lookup requests from responses
and exposes a mailbox to integrate into event loops. When a using a
proxy, each request receives a unique, monotonically increasing 64-bit
ID that is hauled through the response:
// Add a value to a data store (master or clone).
ds->put("foo", 42);
// Create a proxy.
auto proxy = store::proxy{*ds};
// Perform an asynchyronous request to look up a value.
auto id = proxy.get("foo");
// Get a file descriptor for event loops.
auto fd = proxy.mailbox().descriptor();
// Wait for result.
::pollfd p = {fd, POLLIN, 0};
auto n = ::poll(&p, 1, -1);
if (n < 0)
std::terminate(); // poll failed
if (n == 1 && p.revents & POLLIN) {
auto response = proxy.receive(); // Retrieve result, won't block now.
assert(response.id == id);
// Check whether we got data or an error.
if (response.answer)
std::cout << *response.answer << std::endl; // may print 42
else if (response.answer.error() == ec::no_such_key)
std::cout << "no such key: 'foo'" << std::endl;
else
std::cout << "failed to retrieve value at key 'foo'" << std::endl;
}
The proxy provides the same set of retrieval methods as the direct interface, with all of them returning the corresponding ID to retrieve the result once it has come in.
4.3. Intra-store Communication
Broker uses two reserved topics to model communication between masters and clones: M and C. Masters subscribe to M when attached to an endpoint and publish to C to broadcast state transitions to its clones. Clones subscribe to C when attached to an endpoint and publish to M for propagating mutating operations to the master.
These topics also enable clones to find the master without knowing which endpoint it was attached to. When starting a clone, it periodically publishes a handshake to M until the master responds. This rendezvous process also makes it easier to setup cluster instances, because users can attach clones while connection to the master has not been established yet.
The publish/subscribe layer of Broker generally targets loosely coupled deployments and does neither ensure ordering nor guarantee delivery. Without these two properties, masters and clones could quickly run out of sync when messages arrive out of order or get lost. Hence, masters and clones use “virtual channels” to implement reliable and ordered communication on top of the publish/subscribe layer. The master includes a sequence number when publishing to C in order to enable clones to detect out-of-order delivery and ask the master to retransmit lost messages. Cumulative ACKs and per-clone state allow the master to delete transmitted messages as well as to detect unresponsive clones using timeouts.
For the low-level details of the channel abstraction, see the channels section in the developer guide.